阿里巴巴开源Qwen1.5-110B:1100亿参数挑战Meta Llama3-70B性能
|
4月28日消息,阿里巴巴最近公开宣布,他们已成功开源了Qwen1.5系列中的首个千亿参数模型--Qwen1.5-110B。据称,在基础能力的评估测试中,该模型的表现足以媲美meta旗下的Llama3-70B模型,并且在Chat评估中也大放异彩,这包括了MT-Bench和Alpacaeval 2.0两项基准测试。 这款Qwen1.5-110B模型沿用了Qwen1.5系列一贯的Transformer解码器架构,并引入了分组查询注意力(GQA)机制,使得模型在推理时更为高效。这款模型支持长达32K tokens的上下文长度,同时兼容多种语言,包括但不限于英语、中文、法语、西班牙语、德语、俄语、日语、韩语、越南语以及阿拉伯语。
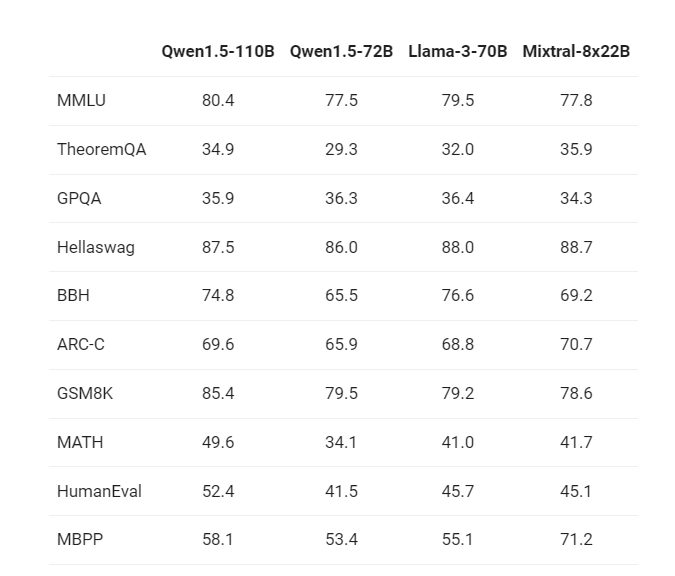
阿里巴巴将Qwen1.5-110B与当前顶尖的语言模型meta-Llama3-70B和Mixtral-8x22B进行了详尽的对比测试。测试结果显示,新的110B模型在基础能力上至少达到了Llama-3-70B模型的水平。阿里巴巴团队指出,他们在这一模型中并未对预训练方法进行大幅调整,因此性能的提升主要归功于模型规模的扩大。
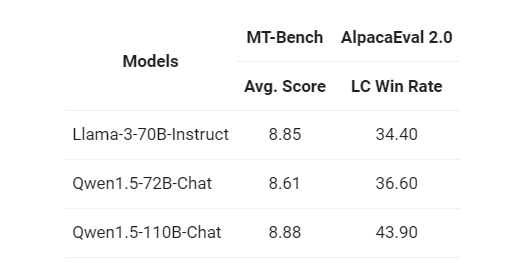
此外,阿里巴巴还在MT-Bench和Alpacaeval 2.0上对其进行了Chat评估。结果显示,与之前发布的72B模型相比,110B模型在这两个Chat模型基准评估中的表现显著更佳。这一持续改善的评估结果表明,即便没有大幅改变训练方法,更强大、规模更大的基础语言模型也能催生出更优秀的Chat模型。 据本站了解,Qwen1.5-110B不仅是Qwen1.5系列中规模最大的模型,更是该系列首个参数超过1000亿的模型。与最近发布的顶尖模型Llama-3-70B相比,其性能表现同样出色,并且明显优于先前的72B模型。这一突破性的进展无疑将为自然语言处理领域带来新的可能性。 |